选择排序的基本思想是:每一趟在剩余未排序的若干记录中选取关键字最小的(也可以是最大的,本文中均考虑排升序)记录作为有序序列中下一个记录。
如第i趟选择排序就是在n-i+1个记录中选取关键字最小的记录作为有序序列中第i个记录。
这样,整个序列共需要n-1趟排序。
简单的选择排序
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到全部待排序的数据元素排完。 选择排序是不稳定的排序方法。 选择排序的思想:选出最小的一个和第一个位置交换,选出其次小的和第二个位置交换 …… 直到从第N个和第N-1个元素中选出最小的放在第N-1个位置。
1 | |
输出结果:
1 | |
容易看出,简单选择排序中,所需进行记录移动的操作次数较少,其最小值为“0”,最大值为3(n-1)。
然而,无论记录的初始序列如何,所需进行的关键字间的比较次数相同,均为n(n-1)/2,因此,总的时间复杂度为O(n²)。
因为简单选择排序没有利用上次选择时比较的结果,所以造成了比较次数多,速度慢。如果能够加以改进,将会提高排序的速度,所以出现了后面的树形选择排序和堆排序。
树形选择排序
树形选择排序(Tree Selection Sort),又称锦标赛排序(Tournament Sort),是一种按照锦标赛思想进行选择排序的方法。
为了减少简单选择排序,我们利用前n-1次比较信息,减少下次选择。类似于锦标赛。根据锦标赛传递关系。亚军只能从被冠军击败的人中选出。
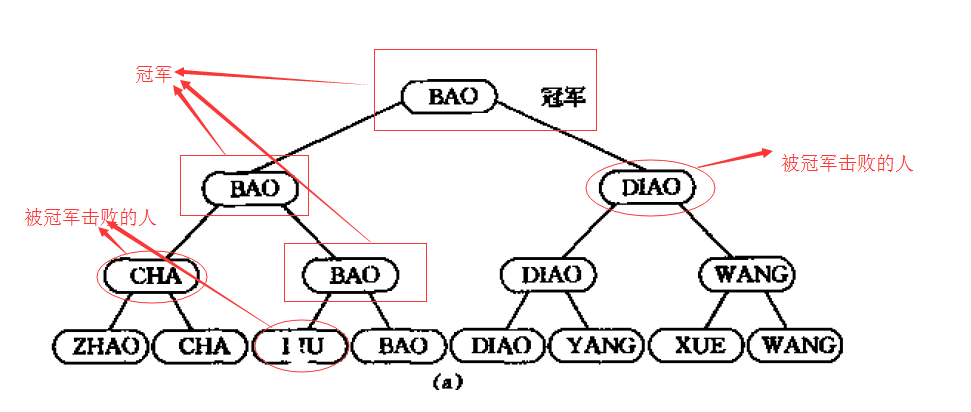
实际算法中,我们把需要比较的记录全部作为叶子,然后从叶子开始两两比较,从底向上最后形成一棵完全二叉树。在我们选择出最小关键字后,根据关系的传递,只需要将最小关键字的叶子节点改成无穷大,重新从底到上比较一次就能够得出次小关键字。
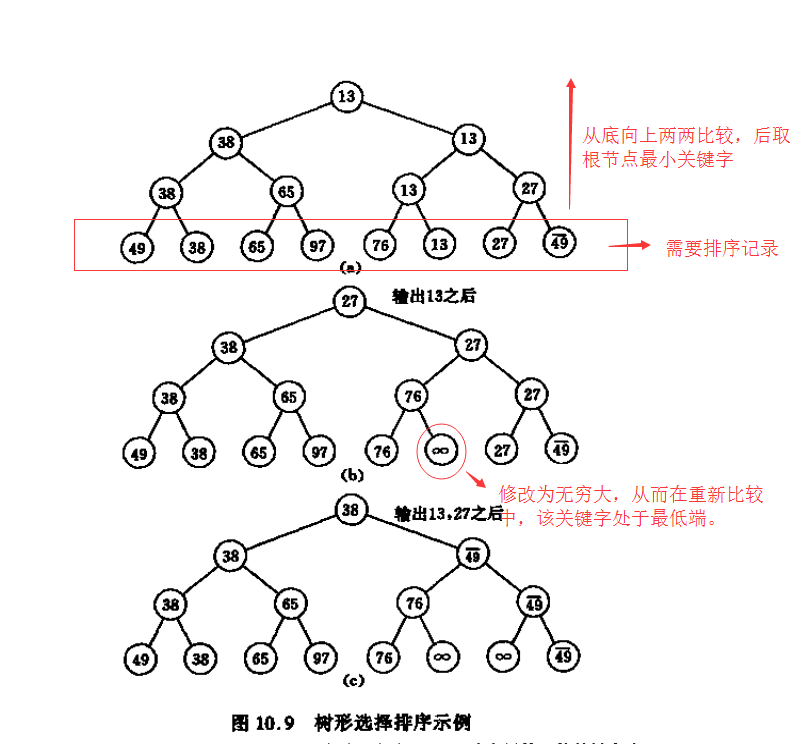
首先对n个记录的关键字进行两两比较,然后在其中[n/2](向上取整)个较小者之间再进行两两比较,如此重复,直至选出最小关键字的记录为止。
这个过程可以用一棵有n个叶子结点的完全二叉树表示。如图中的二叉树表示从8个关键字中选出最小关键字的过程:
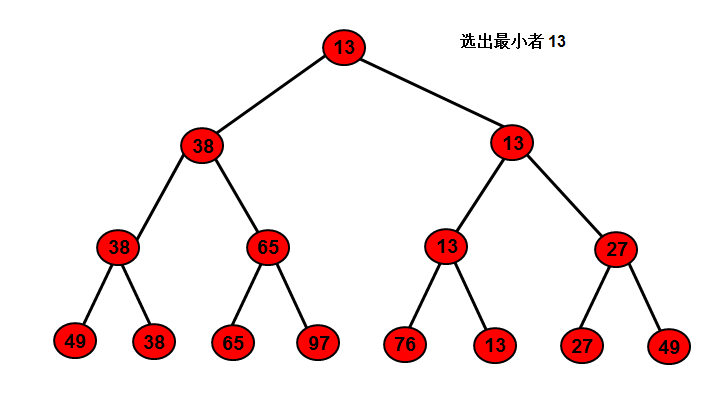
个叶子结点中依次存放排序之前的8个关键字,每个非终端结点中的关键字均等于其左、右孩子结点中较小的那个关键字,则根结点中的关键字为叶子结点中的最小关键字。
在输出最小关键字之后,根据关系的可传递性,欲选出次小关键字,仅需将叶子结点中的最小关键字(13)改为“最大值”,然后从该叶子结点开始,和其左右兄弟的关键字进行比较,修改从叶子结点到根结点的路径上各结点的关键字,则根结点的关键字即为次小值。
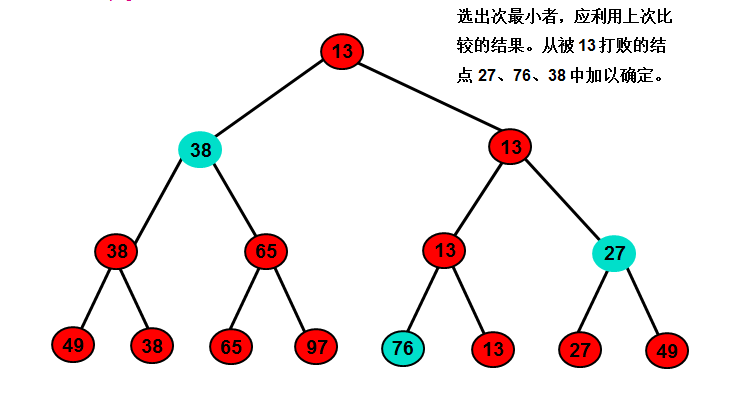
同理,可依次选出从小到大的所有关键字。
由于含有n个叶子结点的完全二叉树的深度为[log2n]+1,则在树形选择排序中,除了最小关键字以外,每选择一个次小关键字仅需进行[log2n]次比较,因此,它的时间复杂度为O(nlogn)。
但是,这种排序方法也有一些缺点,比如辅助存储空间较多,并且需要和“最大值”进行多余的比较。
为了弥补,另一种选择排序被提出——堆排序。
堆排序(Heap Sort)
参考书目:《java程序语言程序设计(进阶篇)》《数据结构与算法分析——C语言描述》
堆排序使用的是二叉堆。它首先将所有的元素添加到一个堆上,然后不断移除最大的元素来获得一个排好序的线性表。(也可以用小顶堆)
二叉堆(binary heap)是一颗具有一下属性的二叉树:
- 形状属性:它是一颗完全二叉树
- 堆属性:每个结点大于或等于它的任意一个孩子
B站有一个很好的视频用来理解:
https://www.bilibili.com/video/av18980178?from=search&seid=9854766405077394358
书中有一段我感觉很好,摘抄下来:
“避免使用第二个数组的聪明做法是利用这样的事实:在每次DeleteMin之后,堆缩小了1.因此,位于堆中最后的单元可以用来存放刚刚删去的元素。”
实现代码自己还没有明白,先粘贴过来反复看理解:
JAVA
1 | |
python的:
1 | |
参考博客:
简单选择排序 Selection Sort 和树形选择排序 Tree Selection Sort