来源于《Asynchronous Methods for Deep Reinforcement Learning》
原文及初步翻译
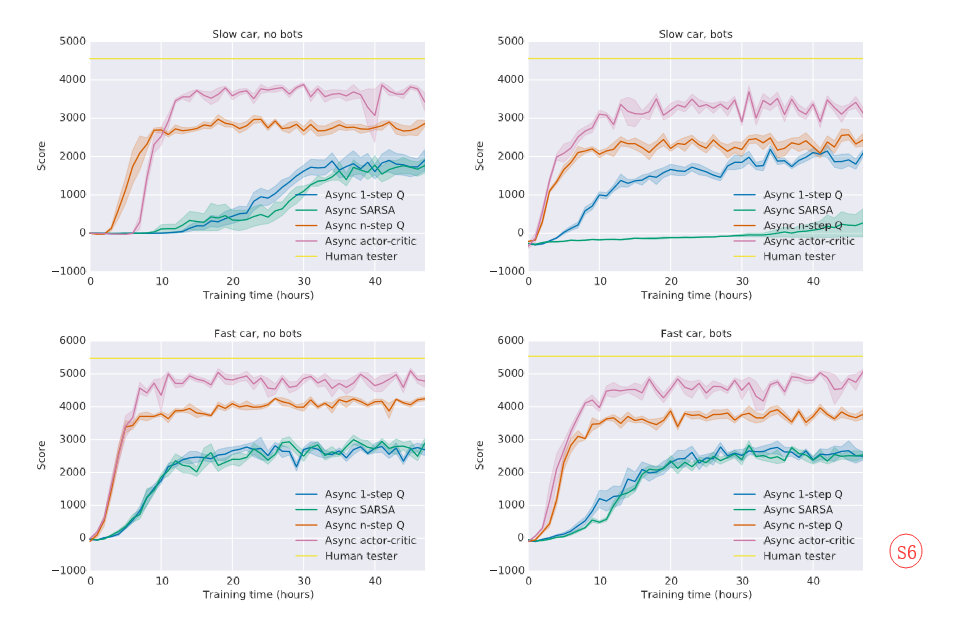
The expertiments performed on a subset(子集;小团体) of Atari games as well as the TORCS experiments (Figure S6) used the following setup(设置). (这些实验运行在Atari游戏环境下,并且TORCS实验也用了这些设置)
Each experiment used 16 actor-learner theads(线程,进程是process) running on a single machine and no GPUs.All methods performed updates after every 5 actions(tmax = 5 and tUpdate = 5) and shared RMSProp(Root Mean Square prop) was used for optimization. The three asynchronous value-based methods used a shared target network that was updated every 40000 frames.(每个实验用了16个actor-learner线程,它可以仅运行在一个没有GPU的机器中。所有的方法每5个动作后执行更新操作,并且都用均方根反向传播方法作为优化器。三个异步值函数(这里我是猜的)共用一个目标网络(什么是目标网络?),这个网络每40000论训练更新一次(这里感觉理解可能有偏差))
The Atari experiments used the same input preprocessing(预处理) as (Mnih et al.,2015) and an action repeat of 4.The agents used the network architecture from (Mnih et al.,2013). The network used a convolutional layer with 16 filters(滤波器,这些层的权重) of size 8X8 with stride 4 ,followed by a convolutional layer with 32 filters of size 4X4 with stride 2,followed by a fully connected layer with 256 hidden units.All three hidden layers were followed by a rectifier nonlinearity(Atari实验用了与15年的那片论文相同的输入预处理并且一个动作重复四次。智体用了13年那篇论文的神经网络结构。这个网络用了一个卷积层,卷积层由16个8X8步幅为4的滤波器,还有一个有32个4X4步幅为2的滤波器组成的卷积层,接着是一个有256个隐藏单元的全联接层,这三个隐藏层都可以跟一个非线性整流器).
The value-based methods had a single linear output unit for each action representing the action-value. The model used by actor-critic agents had two set of outputs - a softmax output with one entry per action representing the probability of selecting the action,and a single linear output representing the value function.All experiments used a discount of γ = 0.99 (折扣因子) and an RMSProp decay factor of α = 0.99 .
The value based methods sampled the exploration rate ε from a distribution taking three values ε1,ε2,ε3 with probabilities 0.4,0.3,0.3. The values of ε1,ε2,ε3 were annealed from 1 to 0.1,0.01,0.5 respectively over the first four million frames.
Advantage actor-critic used entropy regularization(熵正则化) with a weight β =0.01 for all Atari and TORCS experiments. We performed a set of 50 experiments forfive Atari games and every TORCS level,each using a different random initialization and initial learning rate. The initial learning rate was sampled from a *LogUniform*(10-4,10-2)distribution and annealed to 0 over the course of training.Note that in comparisons to prior work we followed standard evaluation protocol and used fixed hyperparameters(混合超参数?).
总结与过程中的疑问
- Torcs是一个video game输入可以是一个视频截图,但是也可以用具体的action来作为输入。
- paper中运用了卷积层,意味着输入是游戏图像??