中国大学mooc课程笔记:《人工智能实践:Tensorflow笔记》曹健 第四讲:神经网络优化 课程地址 课程地址
过拟合
过拟合:神经网络模型在训练数据集上的准确率较高,在新的数据进行预测或分类时准确率较 低,说明模型的泛化能力差。
正则化
正则化:在损失函数中给每个参数 w 加上权重,引入模型复杂度指标,从而抑制模型噪声,减小过拟合。
使用正则化后,损失函数 loss 变为两项之和:
loss = loss(y 与 y_) + REGULARIZER*loss(w)
其中,第一项是预测结果与标准答案之间的差距,如之前讲过的交叉熵、均方误差等;第二项是正则化计算结果。
正则化计算方法:
| ① L1 正则化: 𝒍𝒐𝒔𝒔𝑳𝟏 = ∑𝒊 | 𝒘𝒊 |
用 Tesnsorflow 函数表示:loss(w) = tf.contrib.layers.l1_regularizer(REGULARIZER)(w)
| ② L2 正则化: 𝒍𝒐𝒔𝒔𝑳𝟐 = ∑𝒊 | 𝒘𝒊 | ² |
用 Tesnsorflow 函数表示:loss(w) = tf.contrib.layers.l2_regularizer(REGULARIZER)(w)
用 Tesnsorflow 函数实现正则化:
1 | |
cem (交叉熵cd+softmax函数)的计算已在 → 4.1 节中给出
举例:
用 300 个符合正态分布的点 X[x0, x1]作为数据集,根据点 X[x0, x1]计算生成标注 Y_,将数据集标注为红色点和蓝色点。
标注规则为:当 x02 + x12 < 2 时,y_=1,标注为红色;当 x02 + x12 ≥2 时,y_=0,标注为蓝色。
我们分别用无正则化和有正则化两种方法,拟合曲线,把红色点和蓝色点分开。在实际分类时,如果前向传播输出的预测值 y 接近 1 则为红色点概率越大,接近 0 则为蓝色点概率越大,输出的预测值 y 为 0.5 是红蓝点概率分界线。
matplotlib 模块
Python 中的可视化工具模块,实现函数可视化
函数 plt.scatter():利用指定颜色实现点(x,y)的可视化
1 | |
收集规定区域内所有的网格坐标点:
1 | |
1 | |
例子程序代码如下:
1 | |
两次运行结果:
RUN_first:
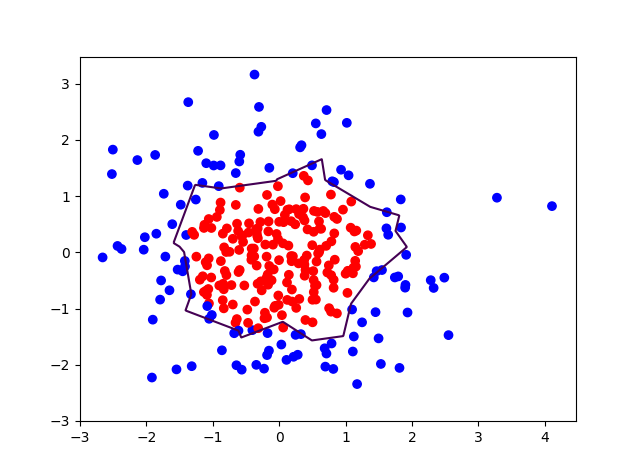
不使用正则化:
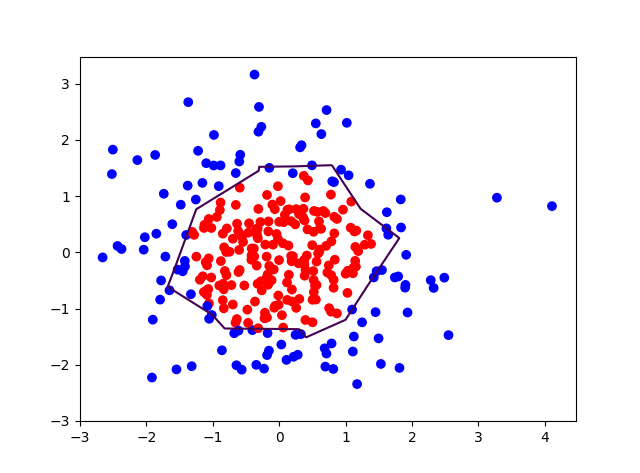
使用正则化:
RUN_second:
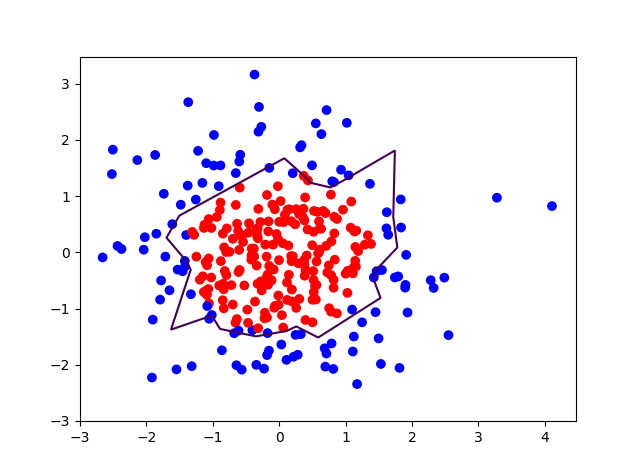
不使用正则化:
使用正则化:
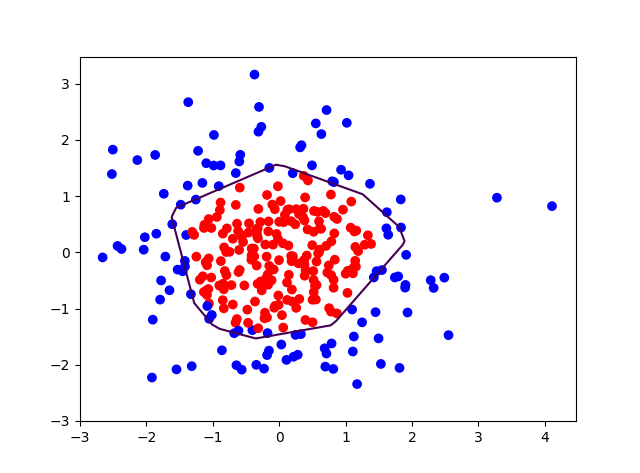
对比无正则化与有正则化模型的训练结果,可看出有正则化模型的拟合曲线平滑,模型具有更好的泛化能力。第二次的运行对比比较明显,不适用正则化的曲线会有“突刺”,而使用正则化则比较平滑。
总结
在运行代码的时候出现没有系统报错,但是运行的时间比较久超过了10分钟,开始想可能是参数错误,但是看到那些输出的消息不是对应的print函数中的内容,思索无果,于是重新对比代码,发现原来是缩进错误,在代码的70~81和103~114行多缩进了两位,导致代码段被for函数囊括,输出了很多无意义的内容。修改缩进后,程序正常运行,可见python的缩进特征带写代码的时候要特别注意一下。
整体来说对正则化的了解还停留在“在损失函数中添加权重”的水平下,仍需多理解。我觉得这mooc这个课程对知识原理得讲解还是不太够,我得基础也不太好,所以买了一本书《Python强化学习实战:应用OpenAI Gym和TensorFlow精通强化学习和深度强化学习》机械工业出版社出版,后续会在更新读书笔记。
在者关于学习环境,在宿舍有电给电脑充电,实际也可以学习,可是思想容易涣散,自己不够专注。这时,只要有点像跑题,就收拾一下去图书馆吧,真心可以专注一些小目标的实现。比方说写一篇博客,整理下内容,读一篇文章,听一段课…这些小内容在图书馆执行得效率特别高,用时也短,所以电脑的电量也够。如果不够得话,这样也有一个具体得任务可以到宿舍在办,有这个小任务约束住自己得思想,在宿舍也就更能控制自己了。