中国大学mooc课程笔记:《人工智能实践:Tensorflow笔记》曹健 第四讲:神经网络优化 课程地址 课程地址
滑动平均:记录了一段时间内模型中所有参数 w 和 b 各自的平均值。利用滑动平均值可以增强模型的泛化能力。
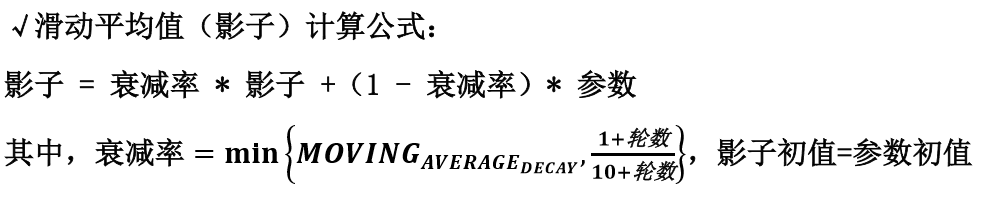
用 Tesnsorflow 函数表示为:
1 | |
其中,MOVING_AVERAGE_DECAY 表示滑动平均衰减率,一般会赋接近 1 的值,global_step 表示当前训练了多少轮。
1 | |
其中,ema.apply()函数实现对括号内参数求滑动平均,tf.trainable_variables()函数实现把所有待训练参数汇总为列表。
1 | |
其中,该函数实现将滑动平均和训练过程同步运行。
查看模型中参数的平均值,可以用 ema.average()函数。
例如:

代码:
1 | |
输出结果:
1 | |
小结
关于模型的泛化能力:
“机器学习的目标很少是去复制训练数据,而是预测新情况。也就是说,我们希望对于训练集之外的输入(其正确的输出并没有在训练集中给出)能够产生正确的输出。训练集上训练的模型在多大程度上能够对新的实例预测出正确输出称为泛化。”
参考资料: http://book.51cto.com/art/200906/130579.htm
PS: 前几天,感觉进度慢,着急看代码,才发现面对自己毫无头绪的知识结构并且学习时间不那么充裕时,着急直接看或者耐心一点一点积累都行不通。要兵分两路,一面学习基础知识,一面探索高层次的思想,这样也许会更好些。前些日子的功夫也不白费,起码配置好了游戏环境,接下来需要一个实例来体验训练游戏的流程,然后阅读例子程序代码,这就需要这些基础的代码积累,毕竟这些是机器学习的原子知识点。再提醒自己一句,不要着急,也不要放松,在有限的时间内做好力所能及的事,别留遗憾。