中国大学mooc课程笔记:《人工智能实践:Tensorflow笔记》曹健 第四讲:神经网络优化 课程地址 课程地址
学习率
学习率 learning_rate:表示了每次参数更新的幅度大小。学习率过大,会导致待优化的参数在最 小值附近波动,不收敛;学习率过小,会导致待优化的参数收敛缓慢。
在训练过程中,参数的更新向着损失函数梯度下降的方向。梯度是损失函数loss的导数。

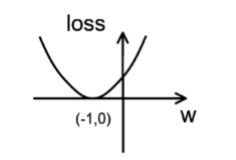
由图可知,损失函数 loss 的最小值会在(-1,0)处得到,此时损失函数的导数为 0,得到最终参数 w = -1。
代码:
1 | |
结果:
1 | |
由结果可知,随着损失函数值的减小,w 无限趋近于-1,模型计算推测出最优参数 w = -1。
学习率的设置
学习率过大,会导致待优化的参数在最小值附近波动,不收敛;学习率过小,会导致待优化的参数收敛缓慢。
1.对于上例的损失函数 loss = (w + 1)²。则将上述代码中学习率修改为 1,其余内容不变。 实验结果如下:
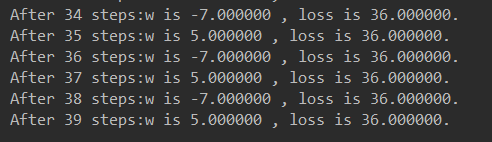
由运行结果可知,损失函数 loss 值并没有收敛,而是在 5 和-7 之间波动。
2.对于上例的损失函数 loss = (w + 1)²。则将上述代码中学习率修改为 0.0001,其余内容不变。 实验结果如下:
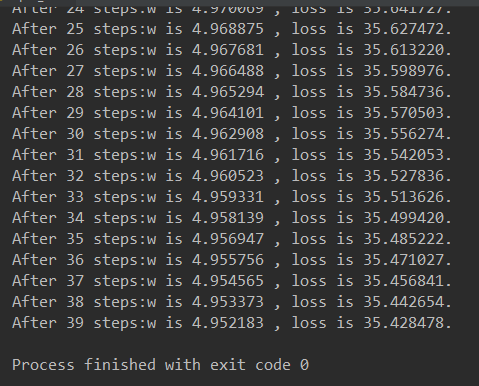
由运行结果可知,损失函数 loss 值缓慢下降,w 值也在小幅度变化,收敛缓慢。
指数衰减学习率
指数衰减学习率:学习率随着训练轮数变化而动态更新 。

例如:
在本例中,模型训练过程不设定固定的学习率,使用指数衰减学习率进行训练。其中,学习率初值设置为 0.1,学习率衰减率设置为 0.99,BATCH_SIZE 设置为 1。
1 | |
1 | |
由结果可以看出,随着训练轮数增加学习率在不断减小.