中国大学mooc课程笔记:《人工智能实践:Tensorflow笔记》曹健 第三讲:Tensorflow框架 课程地址
基于Tensorflow的NN: 用张量表示数据,用计算图搭建神经网络,用会话执行计算图,优化线上的权重(参数),得到模型。
反向传播
反向传播:训练模型参数,在所有参数上用梯度下降,使 NN 模型在训练数据 上的损失函数最小。
损失函数(loss):计算得到的预测值 y 与已知答案 y_的差距。损失函数的计算有很多方法,均方误差 MSE 是比较常用的方法之一。

用 tensorflow 函数表示为:
1 | |
反向传播训练方法:以减小 loss 值为优化目标,有梯度下降、momentum 优化 器、adam 优化器等优化方法。
这三种优化方法用 tensorflow 的函数可以表示为:
1 | |
三种优化方法区别如下:
tf.train.GradientDescentOptimizer()使用随机梯度下降算法,使参数沿着 梯度的反方向,即总损失减小的方向移动,实现更新参数。
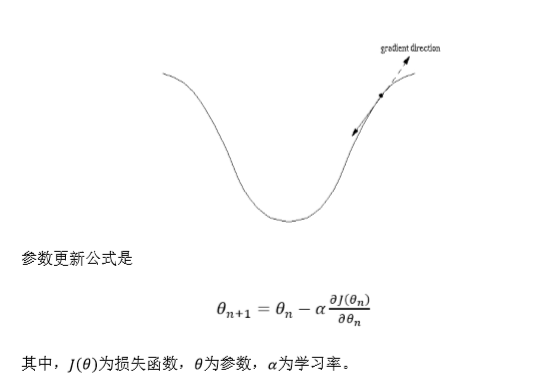
2.
tf.train.MomentumOptimizer()在更新参数时,利用了超参数,参数更新公式
是

3.
tf.train.AdamOptimizer()是利用自适应学习率的优化算法,Adam 算法和随
机梯度下降算法不同。随机梯度下降算法保持单一的学习率更新所有的参数,学
习率在训练过程中并不会改变。而 Adam 算法通过计算梯度的一阶矩估计和二
阶矩估计而为不同的参数设计独立的自适应性学习率。
学习率:决定每次参数更新的幅度。
优化器中都需要一个叫做学习率的参数,使用时,如果学习率选择过大会出现震 荡不收敛的情况,如果学习率选择过小,会出现收敛速度慢的情况。我们可以选 个比较小的值填入,比如 0.01、0.001。
搭建神经网络的八股

举例
随机产生 32 组生产出的零件的体积和重量,训练 3000 轮,每 500 轮输出一次损 失函数。下面我们通过源代码进一步理解神经网络的实现过程: 0.导入模块,生成模拟数据集;
代码:
1 | |
GradientDescentOptimizer:
1 | |
MomentumOptimizer:
1 | |
AdadeltaOptimizer:
1 | |
不同反向传播方法对loss的收敛影响很大,第三个方法与前两个差的很多,也许是当前问题不适合用那种解法。要具体问题具体具体分析。通过这节课,使用tensorflow的基本语法和算法结构都有了些了解,感觉像是在向一种神秘的宝藏慢慢探索,一点一点解密似的。另外,jekyll writer的使用慢慢熟悉了,但markdown的语法还只是掌握了一小部分,慢慢来呗。在最后作个对联:
上联:阳春白雪刮大风
下联:冷冷冷冷冷冷冷
横批:多喝热水