中国大学mooc课程笔记:《人工智能实践:Tensorflow笔记》曹健 第四讲:神经网络优化 课程地址 课程地址
神经元模型
神经元模型:用数学公式表示为:𝐟(∑𝒊𝒙𝒊𝒘𝒊 + 𝐛),f 为激活函数。神经网络是以神经元为基本单元构成的。
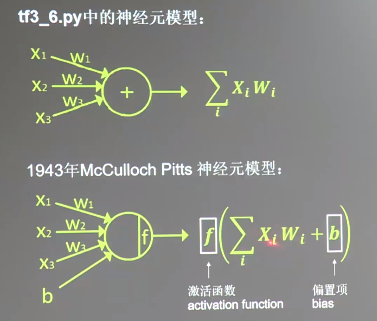
上节课的前向传播的例子是用了第一个神经元模型,后边的模型对其增加了优化,多了激活函数f和偏置项b。吴恩达老师的课程之前听了一小段,讲解了这个神经元模型的改进过程,后续再继续完善。
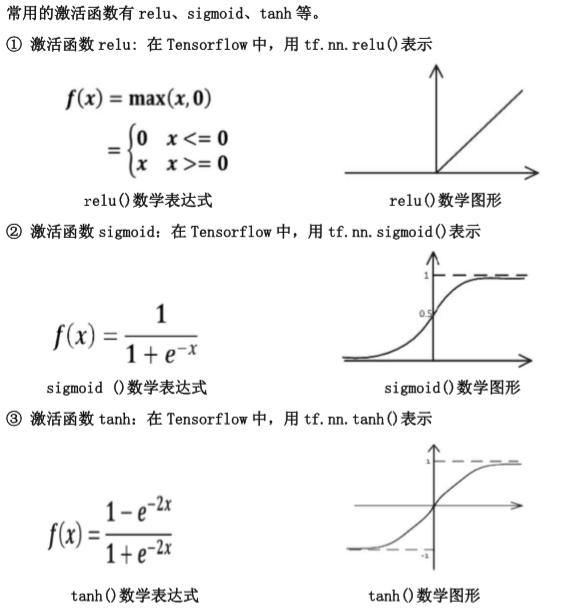
激活函数:引入非线性激活因素,提高模型的表达力。
神经网络的复杂度:可用神经网络的层数和神经网络中待优化参数个数表示
神经网路的层数:一般不计入输入层,层数 = n 个隐藏层 + 1 个输出层
神经网路待优化的参数:神经网络中所有参数 w 的个数 + 所有参数 b 的个数
举例:
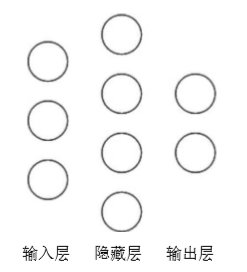
在该神经网络中,包含 1 个输入层、1 个隐藏层和 1 个输出层,该神经网络的层数为 2 层。在该神经网络中,参数的个数是所有参数 w 的个数加上所有参数 b 的总数,第一层参数用三行四列的二阶张量表示(即 12 个线上的权重 w)再加上 4 个偏置 b;第二层参数是四行两列的二阶张量(即8 个线上的权重 w)再加上 2 个偏置 b。
1 | |
损失函数
损失函数(loss): 用来表示预测值(y)与已知答案(y_)的差距。在训练神经网络时,通过不断改变神经网络中所有参数,使损失函数不断减小,从而训练出更高准确率的神经网络模型。
常用的损失函数有均方误差、自定义和交叉熵等
均方误差 mse:n 个样本的预测值 y 与已知答案 y_之差的平方和,再求平均值。
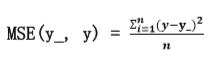
Tensorflow代码:
1 | |
举例:
预测酸奶日销量 y,x1 和 x2 是影响日销量的两个因素。
应提前采集的数据有:一段时间内,每日的 x1 因素、x2因素和销量 y_。采集的数据尽量多。
在本例中用销量预测产量,最优的产量应该等于销量。由于目前没有数据集,所以拟造了一套数据集。利用 Tensorflow 中函随机生成 x1、 x2,制造标准答案 y_ = x1 + x2,为了更真实,求和后还加了正负 0.05 的随机噪声。
我们把这套自制的数据集喂入神经网络,构建一个一层的神经网络,拟合预测酸奶日销量的函数。
1 | |
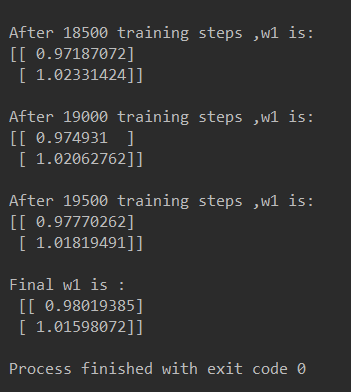
由上述代码可知,本例中神经网络预测模型为 y = w1*x1 + w2*x2,损失函数采用均方误差。通过使
损失函数值(loss)不断降低,神经网络模型得到最终参数 w1=0.98,w2=1.02,销量预测结果为 y =
0.98*x1 + 1.02*x2。由于在生成数据集时,标准答案为 y = x1 + x2,因此,销量预测结果和标准
答案已非常接近,说明该神经网络预测酸奶日销量正确。
在上边这里例子里边我们默认预测多和预测少的影响一样,但在实际情况下,预测多了损失的是成本,预测少了会供不应求,损失的是利润,利润和成本往往不相等。在这这种情况下使用均方误差是没办法计算loss的。
自定义损失函数:根据问题的实际情况,定制合理的损失函数。
对于预测酸奶日销量问题,如果预测销量大于实际销量则会损失成本;如果预测销量小于实际销量则 会损失利润。在实际生活中,往往制造一盒酸奶的成本和销售一盒酸奶的利润是不等价的。因此,需 要使用符合该问题的自定义损失函数。
自定义损失函数为:
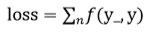
其中,损失定义成分段函数:
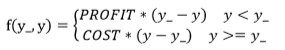
损失函数表示,若预测结果 y 小于标准答案 y_,损失函数为利润乘以预测结果 y 与标准答案 y_之差;
若预测结果 y 大于标准答案 y_,损失函数为成本乘以预测结果 y 与标准答案 y_之差。
用 Tensorflow 函数表示为:
1 | |

类似于三元运算,看是否y比y_大,是的话就COST,不是的话就PROFIT。
1 | |
结果:
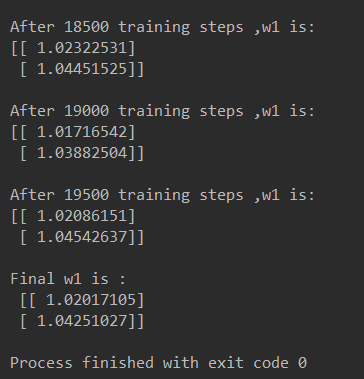
由代码执行结果可知,神经网络最终参数为 w1=1.03, w2=1.05,销量预测结果为 y =1.03*x1 +
1.05*x2。由此可见,采用自定义损失函数预测的结果大于采用均方误差预测的结果,更符合实际需
求。
交叉熵(Cross Entropy):表示两个概率分布之间的距离。交叉熵越大,两个概率分布距离越远,两 个概率分布越相异;交叉熵越小,两个概率分布距离越近,两个概率分布越相似。
交叉熵计算公式:𝐇(𝐲_ , 𝐲) = −∑𝐲_ ∗ 𝒍𝒐𝒈 𝒚
用 Tensorflow 函数表示为:
1 | |
例如:
两个神经网络模型解决二分类问题中,已知标准答案为 y_ = (1, 0),第一个神经网络模型预测结果为y1=(0.6, 0.4),第二个神经网络模型预测结果为 y2=(0.8, 0.2),判断哪个神经网络模型预测的结果更接近标准答案。
根据交叉熵的计算公式得:
H1((1,0),(0.6,0.4)) = -(1*log0.6 + 0*log0.4) ≈ -(-0.222 + 0) = 0.222
H2((1,0),(0.8,0.2)) = -(1*log0.8 + 0*log0.2) ≈ -(-0.097 + 0) = 0.097
由于 0.222>0.097,所以预测结果 y2 与标准答案 y_更接近,y2 预测更准确。
softmax 函数:将 n 分类的 n 个输出(y1,y2…yn)变为满足以下概率分布要求的函数。
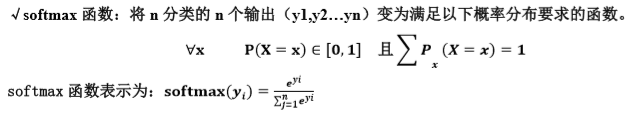
softmax 函数应用:在 n 分类中,模型会有 n 个输出,即 y1,y2…yn,其中 yi 表示第 i 种情况出现的可 能性大小。将 n 个输出经过 softmax 函数,可得到符合概率分布的分类结果。
在 Tensorflow 中,一般让模型的输出经过 sofemax 函数,以获得输出分类的概率分布,再与标准 答案对比,求出交叉熵,得到损失函数,用如下函数实现:
1 | |
对里边的数学公式概念了解的不清楚,会运用的水平,多体会。 2019/2/17 交叉熵这个概念在《数学之美》中有提及,交叉熵也叫相对熵。 2019/2/18